
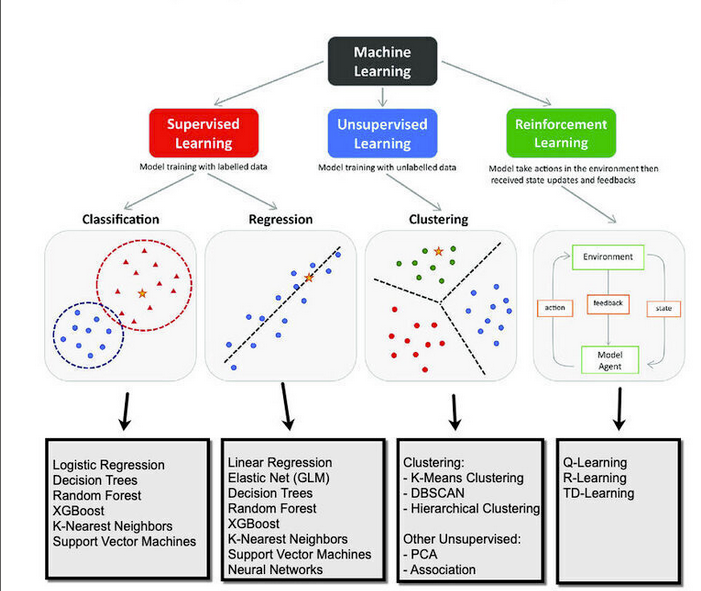
Supervised learning uses labeled data to learn a mapping from inputs to known outputs, while unsupervised learning uses unlabeled data to discover hidden patterns or structure in the data. Both are core ideas in machine learning and appear in everything from recommendation systems to anomaly detection.
What is supervised learning?
Supervised learning is a type of machine learning where each training example comes with an input and a correct output label. The model learns from these examples so it can predict the label for new, unseen inputs.byjus+1
Key characteristics:
- Uses labeled data (features + target), such as “email text → spam/not spam.
- Main goal is prediction or classification: given x, estimate
- Typical tasks:
- Classification (spam detection, image recognition, fraud detection).
- Regression (price prediction, demand forecasting, time-to-delivery).
Common supervised algorithms include linear regression, logistic regression, decision trees, random forests, support vector machines and neural networks.
What is unsupervised learning?
Unsupervised learning works with data that has no labels, meaning only input features are available. The algorithm tries to find structure in the data on its own, such as groups, patterns or low‑dimensional representations.ibm+1
Key characteristics:
- Uses unlabeled data where only x is known and no target y is provided.
- Main goal is discovering hidden patterns, clusters or relationships.
- Typical tasks:
- Clustering (grouping customers by behavior, segmenting users).
- Association (finding items frequently bought together).
- Dimensionality reduction (compressing features while preserving structure).
Popular unsupervised algorithms include k‑means clustering, hierarchical clustering, DBSCAN, principal component analysis (PCA) and association rule mining.
Supervised vs unsupervised: key differences
| Aspect | Supervised learning | Unsupervised learning |
|---|---|---|
| Data type | Labeled (inputs + known outputs). | Unlabeled (only inputs, no targets). |
| Main goal | Predict outputs or classify new data. | Discover hidden patterns or structure. |
| Typical tasks | Classification, regression. | Clustering, association, dimensionality reduction. |
| Human involvement | Requires labeled training set, more manual effort. | Less manual labeling; model explores data automatically. |
| Output | Concrete predictions or class labels. | Insights, groups, patterns. |
Supervised learning is preferred when you know what you want to predict and have historical examples. Unsupervised learning is ideal when you want to explore data, segment users or detect unusual behavior without predefined labels.